参考论文 Online, Asynchronous Schema Change in F1,本文就不详细介绍了。
算法的核心主要有两点:
tidb 按照论文中的要求实现了 schema lease,保证所有 tidb 节点中同时只存在两个相邻的 schema 版本,但仍然会遇到一些问题。
在分布式事务下,「数据组装和写入」以及「数据提交和可见」是两个不同的时间点,而 schema lease 只能保证某一个时间点下的 schema 版本。所以当数据提交时,schema lease 所保护的 schema 版本可能已经不是写入时的版本了,那就破坏了论文中的保证。
以加索引为例,在这里举两个实际的例子。
加索引的状态变更流程为:
1
Absent => Delete Only => Write Only => Reorg => Public
考虑以下时序一:
考虑以下时序二:
可以发现,这两个时序都是在 schema lease 推进 schema 版本到 N+1 后,事务提交了 schema 版本为 N-1 的数据。
对于同步提交,tidb 通过在 2pc 时进一步检查 schema 版本避免该问题。
具体的时机是在 prewrite 成功且获取 commit ts 之后进行检查,如果当前通过 schema lease 获取的 schema 版本和事务创建时的版本相同,说明全局的 schema 版本最多只有可能推进一个版本,便仍然是可兼容的版本,此时便可以继续 commit,否则本次 2pc 需要失败并重试。
实际检查会更精细一些,包括推进的 schema 版本是否和本次操作的表有关系,不过这些不在本文的核心内容中,就不详述了。
上面说完了同步提交,再说说 tidb 5.0 实现的异步提交,同样仅简述一些必要的背景知识。具体可以参考官方博客中的介绍或是分布式事务的时间戳这篇文章。
从流程上来看,同步提交和异步提交的区别为:
从正确性来看,异步提交的核心实现是 commit ts 由 prewrite 阶段动态计算得出,也就是 commit 的结果和「定序」均在 prewrite 时已经确定并持久化,之后便不可以再更改。
异步提交的实现在 prewrite 完成后便将结果返回给了客户端,而回复就意味着承诺,也就表示之后的结果一定不能改变。
如果还采用同步提交的方案,在 commit 之前才检查 schema 版本,那么就会出现已经返回成功后,检查 schema 版本却失败了的问题,此时违背了之前的承诺。
看到此处读者可能会想,那在 prewrite 成功返回结果之前就检查 schema 版本,如果检查失败就直接返回失败,不再走 commit 流程,是否就能解决这个问题了。
很遗憾,答案还是不能,考虑一下极端情况,tidb 节点完成检查 schema 版本后返回成功,但是在发起 commit 之前宕机了。之后的恢复流程需要再次检查 schema 版本(因为不知道是检查前宕机还是检查后宕机),此时有可能检查 schema 版本失败并回滚,同样违背了之前的承诺。
考虑一下,为什么第一次检查 schema 版本成功后,第二次检查 schema 版本会失败呢?
因为同步提交下的 schema 版本检查实际是一个「单向屏障」,在获取 commit ts 之后获取最新的 schema 版本并检查,只能做单向保证:「通过检查表示该 commit ts 一定符合要求」,而不是「符合要求的 commit ts 都能通过检查」。因为获取 commit ts 和获取最新的 schema 版本中间会有缝隙,检查失败不一定不符合要求。
因此,即使 commit ts 不变,随着时间的推移,schema 检查会逐渐趋向于失败,而此时的失败就是被误判的场景。
那么是否有办法将这个检查变为一个「双向屏障」,即保证 commit ts 和 schema 版本一定是一一对应的,只要 commit ts 不变,对应的 schema 版本也就不会变,那么检查 schema 版本也会变为确定的结果。
在此介绍 tidb 的第一版解决方案,主要的工作在 txn: add schema version check for async commit recovery #20186 下。
其核心改动是增加了 checkSchemaVersionForAsyncCommit 函数,实现异步提交下的 schema 版本检查,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
// checkSchemaVersionForAsyncCommit is used to check schema version change for async commit transactions
// only. For async commit protocol, we need to make sure the check result is the same during common execution
// path and the recovery path. As the schema lease checker has a limited size of cached schema diff version, it's
// possible the schema cache is changed and the schema lease checker can't decide if the related table has
// schema version change. So we just check the version from meta snapshot, it's much stricter.
func checkSchemaVersionForAsyncCommit(ctx context.Context, startTS uint64, commitTS uint64, store Storage) (bool, error) {
if commitTS > 0 {
snapshotAtStart, err := store.GetSnapshot(kv.NewVersion(startTS))
if err != nil {
logutil.Logger(ctx).Error("get snapshot failed for resolve async startTS",
zap.Uint64("startTS", startTS), zap.Uint64("commitTS", commitTS))
return false, errors.Trace(err)
}
snapShotAtCommit, err := store.GetSnapshot(kv.NewVersion(commitTS))
if err != nil {
logutil.Logger(ctx).Error("get snapshot failed for resolve async commitTS",
zap.Uint64("startTS", startTS), zap.Uint64("commitTS", commitTS))
return false, errors.Trace(err)
}
schemaVerAtStart, err := meta.NewSnapshotMeta(snapshotAtStart).GetSchemaVersion()
if err != nil {
return false, errors.Trace(err)
}
schemaVerAtCommit, err := meta.NewSnapshotMeta(snapShotAtCommit).GetSchemaVersion()
if err != nil {
return false, errors.Trace(err)
}
if schemaVerAtStart != schemaVerAtCommit {
logutil.Logger(ctx).Info("async commit txn need to rollback since schema version has changed",
zap.Uint64("startTS", startTS), zap.Uint64("commitTS", commitTS),
zap.Int64("schema version at start", schemaVerAtStart),
zap.Int64("schema version at commit", schemaVerAtCommit))
return false, nil
}
}
return true, nil
}
这个实现使用了 start ts 和 commit ts 进行快照读获取当时的 schema 版本,这样当 commit ts 确定时(异步提交在 prewrite 完成后即确定 commit ts,并且在故障恢复时也可以通过持久化的数据计算出相同的值),schema 版本也是确定的,不受真正提交和检查 schema 版本时机的影响。
不过这个方案的缺点也很明显,在检查 schema 版本时需要进行两次快照读(理论上可以合并为一次),在主路径上增加 rpc 的开销并不小,可能会影响到异步提交带来的性能提升,因此这个方案也没能成为最终方案。
鉴于方案一有一些不完美的地方,tidb 在 ddl, tikv: add delay during AddIndex DDL and remove schema check for async commit #20550 中又实现了一个新的方案,并沿用至今。
主要实现是增加了 calculateMaxCommitTS 函数,用于在 prewrite 前计算一个确定合法的 commit ts 上界,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
func (c *twoPhaseCommitter) calculateMaxCommitTS(ctx context.Context) error {
// Amend txn with current time first, then we can make sure we have another SafeWindow time to commit
currentTS := oracle.ComposeTS(int64(time.Since(c.txn.startTime)/time.Millisecond), 0) + c.startTS
_, _, err := c.checkSchemaValid(ctx, currentTS, c.txn.schemaVer, true)
if err != nil {
logutil.Logger(ctx).Info("Schema changed for async commit txn",
zap.Error(err),
zap.Uint64("startTS", c.startTS))
return err
}
safeWindow := config.GetGlobalConfig().TiKVClient.AsyncCommit.SafeWindow
maxCommitTS := oracle.ComposeTS(int64(safeWindow/time.Millisecond), 0) + currentTS
logutil.BgLogger().Debug("calculate MaxCommitTS",
zap.Time("startTime", c.txn.startTime),
zap.Duration("safeWindow", safeWindow),
zap.Uint64("startTS", c.startTS),
zap.Uint64("maxCommitTS", maxCommitTS))
c.maxCommitTS = maxCommitTS
return nil
}
首先对当前时间生成一个当前时间的 tso(在 start ts 的基础上偏移事务创建时间),如果当前时间通过了 schema 版本检查,就在当前时间的基础上增加 2s(safe window)作为 max commit ts。之后在 prewrite 计算 commit ts 时,如果计算出的 commit ts 超过了 max commit ts,则返回失败。
除此之外,在执行 reorg 时也需要等待 2.5s(2s 的 safe window + 0.5s 的时钟漂移) 才能真正开始:
1
2
3
4
5
6
7
8
9
10
11
12
13
func (w *worker) runReorgJob(t *meta.Meta, reorgInfo *reorgInfo, tblInfo *model.TableInfo, lease time.Duration, f func() error) error {
// Sleep for reorgDelay before doing reorganization.
// This provides a safe window for async commit and 1PC to commit with an old schema.
// lease = 0 means it's in an integration test. In this case we don't delay so the test won't run too slowly.
if lease > 0 {
cfg := config.GetGlobalConfig().TiKVClient.AsyncCommit
reorgDelay := cfg.SafeWindow + cfg.AllowedClockDrift
logutil.BgLogger().Info("sleep before reorganization to make async commit safe",
zap.Duration("duration", reorgDelay))
time.Sleep(reorgDelay)
}
// ...
}
我不太清楚该如何系统性的描述整个方案的正确性,因此下面的内容是以 Q&A 的方式进行记录。
以下部分疑惑请教了上述 PR 的原作者 @sticnarf,感谢他的解答。
最开始我以为设置的 2s 是依赖了 schema lease 的实现,即每个操作都会等 2 * leasa 的时间。后来想到 tidb 支持在 pd 上注册和监听 schema 版本变更以加速推进 ddl,实际并没有这个保证(并且 lease time 是可配的,肯定不会在代码里写死 2s)。
所以这应该是一个经验值,认为异步提交的事务在 prewrite 阶段基本都会在 2s 内完成,并且代码中动态计算了 current ts 而不是直接用 start ts 也是为了尽量减少事务时间的限制,对长事务更加友好。
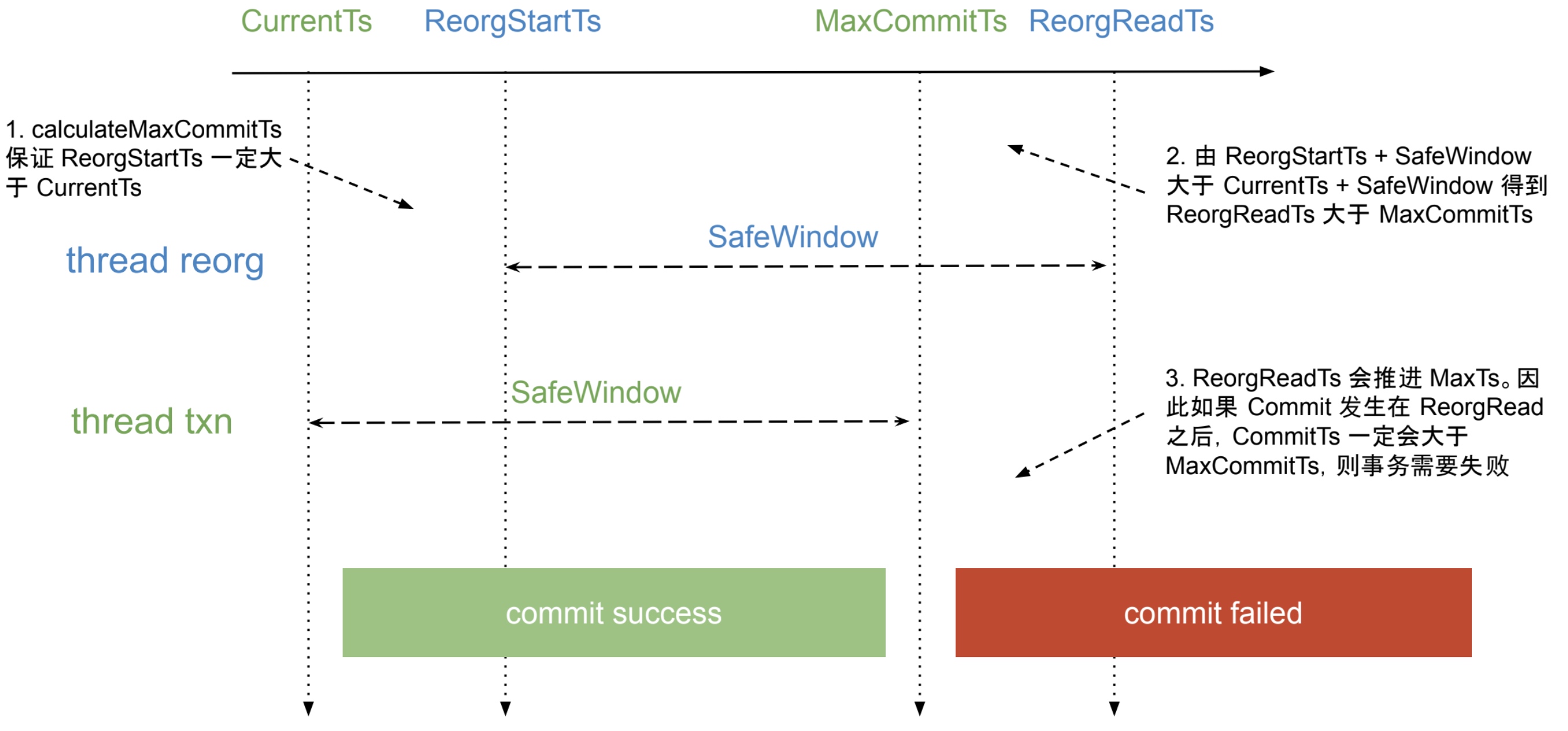
在异步提交下 reorg 出现问题的时序是确定的:
根据异步提交的实现,reorg 扫描时会将 tikv 对应的 max ts 推进到 reorg read ts,而之后 prewrite 时事务 commit ts 的计算区间即为 [reorg read ts, max commit ts),此时如果需要拦截住所有事务提交,就需要让 max commit ts 小于等于 reorg read ts。
而从上面的时序中可以得到 reorg read ts 一定大于 current ts,那么 reorg read ts + 2s 则一定大于 max commit ts,基于此使得 reorg 在执行前也需要等待 2s。
注意上述的前提都是不考虑时钟漂移的情况下。
有两处地方会受到始终漂移的影响:
只要发生了上述任意一种场景,都会导致 max commit ts < reorg read ts 这个保证不成立,也就有可能导致索引丢失。
所以,依赖 tso 和现实时间进行“绑定”是一个有风险的行为,例如:从 pd 拿到一个 tso A,在其基础上增加 2s 得到 A’,然后在本地 sleep 2.1s 后从 pd 在拿到 tso B,此时无法保证 B 一定比 A’ 更大。
在本文的最开始介绍了发生错误的两个时序,在不同方案中检测出问题的时机也是不同的:
calculateMaxCommitTS 时就能检查出来(因为两个事务都是写操作),只有时序一才需要通过 reorg 的等待进行保证(因为 reorg 是读操作)